
Runpod emerges as a beacon of innovation in cloud computing, specifically tailored to empower AI, ML, and general computational tasks. Engineered to harness the power of GPU and CPU resources within Pods, it offers a seamless blend of efficiency and flexibility through serverless computing options.
Deploying a Large Language Model (LLM) on RunPod
Leveraging the prowess of RunPod for deploying Large Language Models (LLMs) unveils a realm of possibilities in distributed environments.
How to approach it?
- Setup Environment: Ensure that your RunPod environment is properly set up with the necessary dependencies and resources to run the LLM. This includes having the required libraries, such as TensorFlow or PyTorch, installed, as well as allocating sufficient memory and processing power.
- Model Selection: Choose the specific LLM model you want to deploy. This could be GPT-3.5, GPT-4, or any other variant depending on your requirements and available resources.
- Model Serialization: Serialize the chosen LLM model into a format that can be easily loaded and used within your RunPod environment. This typically involves saving the model weights and architecture in a compatible format, such as a TensorFlow SavedModel or PyTorch state dictionary.
- Integration with RunPod: Integrate the serialized model into your RunPod environment. This may involve copying the model files into the appropriate directory within the RunPod filesystem and ensuring that any necessary dependencies are also included.
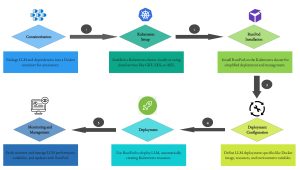
- API Setup: Set up an API endpoint within your RunPod environment to interface with the deployed LLM model. This API will receive input text and return the model’s generated response. You can use frameworks like Flask or FastAPI to create the API endpoints.
- Testing and Optimization: Test the deployed model to ensure that it is functioning correctly within the RunPod environment. You may need to optimize the model’s performance based on the available resources and constraints of the RunPod.
- Deployment: Once everything is set up and tested, deploy the LLM on the RunPod environment. Monitor its performance and make any necessary adjustments to ensure optimal operation.
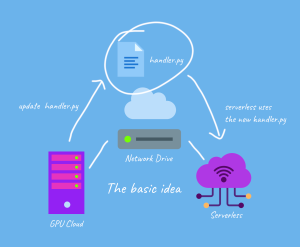
- Scaling and Maintenance: As needed, scale the deployed LLM to handle increased demand, and regularly maintain the system to ensure continued reliability and performance.
Why to use RunPod?
- Optimized for AI and ML: Specialized infrastructure and tooling for optimal performance.
- Unified GPU and CPU Support: Harness both resources for diverse computational tasks.
- Simplified Deployment: Pod-based execution and serverless options for easy deployment.
- Scalability and Cost-Efficiency: Dynamically scale resources and optimize cost effectiveness.
- Community and Support: Access resources, tutorials, and expert support for collaboration and innovation.
In the ever-evolving landscape of AI and ML, RunPod emerges as a game-changer, offering a bespoke cloud computing platform tailored to meet the demands of modern computational tasks. By seamlessly integrating LLMs into its environment, RunPod paves the way for groundbreaking advancements in distributed computing. With its optimized infrastructure, unified support for GPU and CPU resources, simplified deployment options, and robust scalability, RunPod stands as the epitome of efficiency and innovation in cloud computing for AI and ML. Embrace RunPod today and embark on a journey towards unparalleled performance and productivity in your computational endeavors.