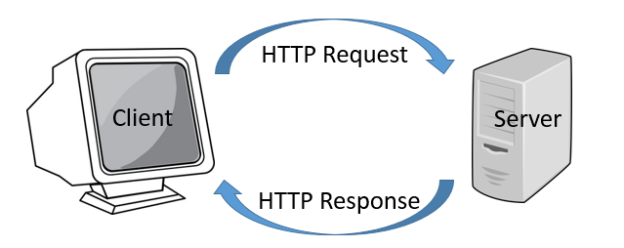
Introduction
Before we dive into understanding about HTTP, let’s try to understand meaning of the word “Protocol”.
A Protocol is a set of rules that we use for specific purposes. In the current scenario, when we are talking about protocols, it is about communication- the way we talk to each other. For instance, we speak in English and because you understand English, you can understand. Here English is the protocol. The moment we start speaking in a language that you don’t understand; the protocol beats its purpose. Thus, we need both the parties to agree to a set of rules for the communication to take place.
Now, talking about the web, multiple protocols are used to communicate. Primarily for end users the most important and visible protocols are HTTP and HTTPS. Though there are many other protocols as well, but HTTP and HTTPS protocols cater to most of the population.
Now, what does HTTP mean?
HTTP is hypertext transfer protocol. As we all know, computers work in a language of 1’s and 0’s i.e. Binary language.
Let’s say I want to write ‘a’. Now, if 0 stands for ‘a’, 1 stands for ‘b’, and 01 stands for ‘c’, I can infer that a combination of 0’s and 1’s can construct a word as well. In this case, the text is already constructed and is being sent on the wire. Here, what is being transferred is text (in form of bytes). I am emphasising on ‘text’ because this text is interpreted by the browser and the moment browser interprets it, it becomes hypertext, and the protocol that transfers the text is referred to as hypertext transfer protocol – HTTP.
NOTE: Hyper is also a prefix, from the Greek hyper- meaning over, above, or excessive, used in such terms as hypertext (text that extends to point to or include other text).
HTTP Overview
Basically, HTTP is a TCP/IP based communication protocol, that is used to deliver data (HTML files, image files, query results, etc.) on the World Wide Web. This is an Application Layer protocol. The default port is TCP 80, but other ports can be used as well. It provides a standardized way for computers to communicate with each other. HTTP specification specifies how clients’ request data will be constructed and sent to the server, and how the servers respond to these requests.
Basic Features
There are three basic features that make HTTP a simple but powerful protocol:
- HTTP is connectionless*:The HTTP client, i.e., a browser initiates an HTTP request and after a request is made, the client disconnects from the server and waits for a response.
- HTTP is media independent:It means, any type of data can be sent by HTTP if both the client and the server know how to handle the data content. It is required for the client as well as the server to specify the content type using appropriate MIME-type.
- HTTP is stateless:As mentioned above, HTTP is connectionless and it is a direct result of HTTP being a stateless protocol. The server and client are aware of each other only during a current request. Afterwards, both forget about each other. Due to this nature of the protocol, neither the client nor the browser can retain information between different requests across the web pages.
* HTTP/1.0 uses a new connection for each request/response exchange, where as
HTTP/1.1 connection may be used for one or more request/response exchanges.
HTTP Version
HTTP uses a <major>.<minor> numbering scheme to indicate versions of the protocol.
Here is the general syntax of specifying HTTP version number:
![]()
Example
![]()
HTTPS
Why we need HTTPS?
When you log into your site, your login credentials are easy to intercept if not encrypted with HTTPS. The “password” field may show only circles in your Web browser, but your actual password is transmitted “in the clear” across the Internet for anyone to see. So, sending data on internet over HTTP is like sending item from courier without security. Criminals can access that traffic in several ways, including monitoring WiFi connections, having an inside position at an Internet service provider or backbone network, or by hacking into routers across the Internet so they can watch the traffic that flows across them.
So, new protocol introduced to handle valuable sensitive data. This protocol is known as SSL (Secured Socket Layer).
HTTPS= HTTP + SSL (HTTP protocol working in tandem with SSL)
So, what is SSL? Before we understand SSL, first we need to understand Cryptography.
What is Cryptography?
It is basically a science of hiding information. It’s a method of storing and transmitting data in a form so that only those for whom it is intended can read and process it.
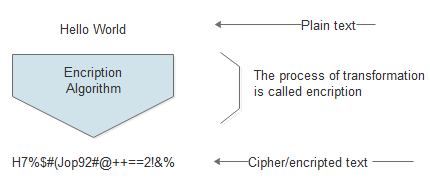
Fig 4.2
In fig 4.2, we have a text “Hello World” that is being encrypted by algorithm and the output text after the encryption is called cipher/encrypted text as sown in above diagram.
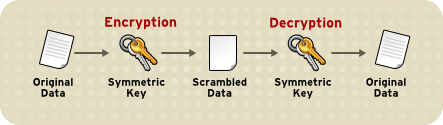
Sometimes encryption needs a key to encrypt data. Data encrypted via key can be send to respective consumer who can decrypt to its normal form via same kay, here it is called semantic key that is used for both encryption and decryptions.
So, one key can be shared among all the users but this is situation like all the houses have lock and each have key and any one can open any’s lock. So, cryptography come to rescue again. In cryptography, there is a way to encrypt with one key and decrypt with another key.
Communication between browser and server
Coming back around SSL Protocol, so following steps happens when a data is send to serve.
- When we type URL with HTTPS then bowser connect over TCP port
443 (default port for HTTPS) over transport layer. - After the connection is successful the next, SSL handshake starts.
- Server response with “server HELLO message”.
- Server send digital certificate signed by signing authority (Verisign etc.)
- Then server sends “server HELLO done” message hinting browser to start processing at its end.
- Browser response to the server by sending “Certificate verify” message. Its means server is verified.
- Then client sends “Changed cipher specification”. It means the data send over HTTPS by browser will be encrypted.
- After that browser sends the “Finish Message” which have digest message that contains all the communication held till now.
- Now server sends “Change cipher specification” message.
- Again, server sends “Finish message” which also contains all the information of the communication held till now.
The purpose of Finish message is, confirmation that all the previous message not conferred / tempered. At this point SSL handshake is complete. The client sends Semantic secret key to server for encryption and decryption.
So, after that actual message shared by browser to the server and this way our data is secured via HTTPS over internet.
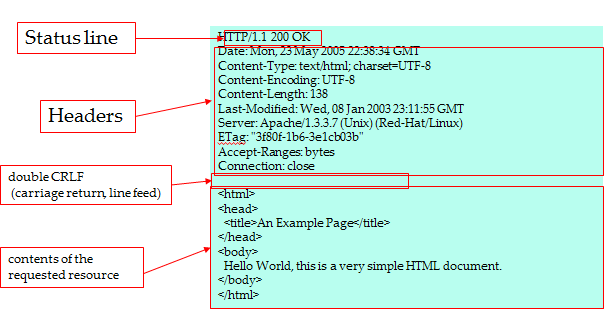
Message Format
HTTP requests and HTTP responses use a generic message format of RFC 822 for transferring the required data. This generic message format consists of the following four items.
- A Start-line
- Zero or more header fields followed by CRLF
- An empty line (i.e., a line with nothing preceding the CRLF)
- indicating the end of the header fields
- Optionally a message-body
Message Start-Line
A start-line will have the following generic syntax:
![]()
We will discuss Request-Line and Status-Line while discussing HTTP Request and HTTP Response messages respectively. For now, let’s see the examples of start line in case of request and response:
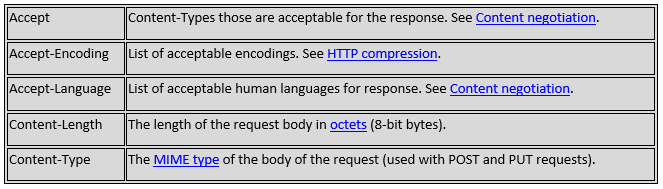
Header Fields
HTTP header fields provide required information about the request or response, or about the object sent in the message body.
Syntax of the header field is as follow![]()
HTTP Request message
The above image is explaining all the components of the request. Following is separate example of GET and POST.
GET Request example
Here we are not sending any request data to the server because we are fetching a plain HTML page from the server. Connection is a general-header, and the rest of the headers are request headers.
The following example shows how to send form data to the server using request message body:
Post Request example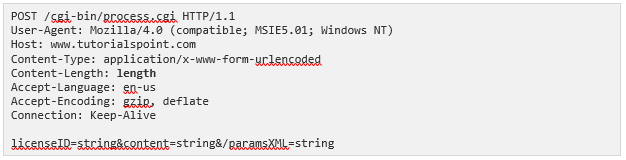
Here the given URL /cgi-bin/process.cgi will be used to process the passed data and accordingly, a response will be returned. Here content-type tells the server that the passed data is a simple web form data and length will be the actual length of the data put in the message body.
After receiving and interpreting a request message, a server responds with an HTTP response message: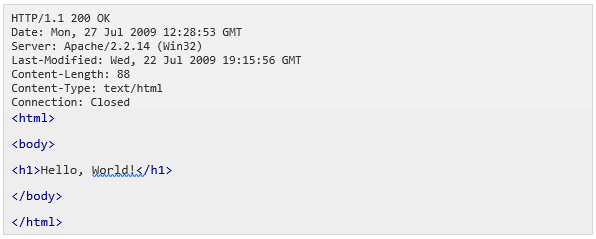
 The following example shows an HTTP response message displaying error condition when the web server could not find the requested page:
The following example shows an HTTP response message displaying error condition when the web server could not find the requested page: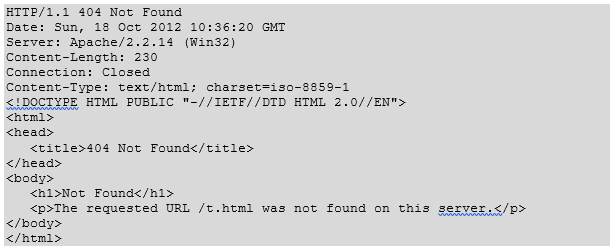
Following is an example of HTTP response message showing error condition when the web server encountered a wrong HTTP version in the given HTTP request: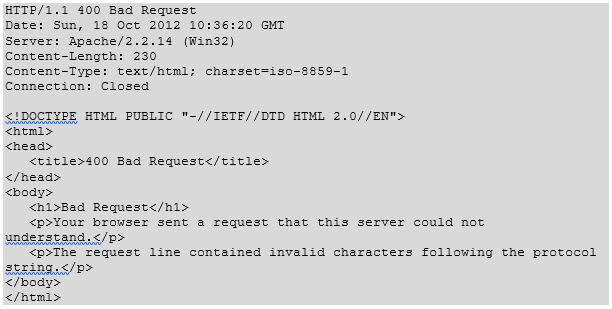

HTTP status codes are extensible and HTTP applications are not required to understand the meaning of all registered status codes. A list of all the status codes has been given in a status code topic defined down the line of document
HTTP – Methods
The set of common methods for HTTP/1.1 is defined below and this set can be expanded based on requirements. These method names are case sensitive and they must be used in uppercase.

GET Method
A GET request retrieves data from a web server by specifying parameters in the URL portion of the request. This is the main method used for document retrieval. The following example makes use of GET method to fetch hello.htm:
The server response against the above GET request will be as follows: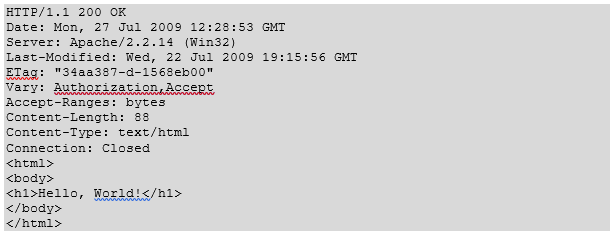
POST Method
The POST method is used when you want to send some data to the server, for example, file update, form data, etc. The following example makes use of POST method to send a form data to the server, which will be processed by a process.cgi and finally a response will be returned: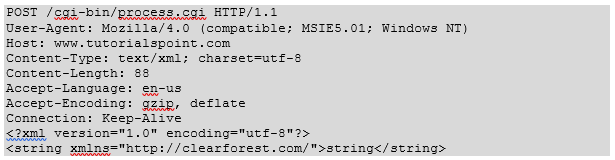
The server side script process.cgi processes the passed data and sends the following response: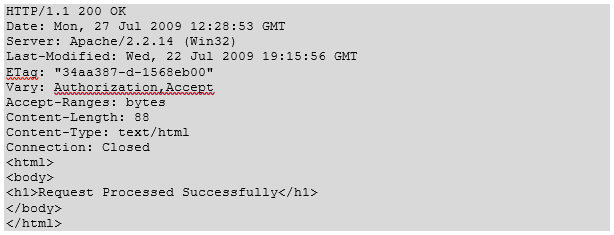
HTTP – Status Codes
As I described above status code in brief, now we are going to see all the codes with its description. Status code play role in response and the browser or user behaves according to the status code received from the server.
1XX Information:
2XX Information:
3XX Information:

4XX Information: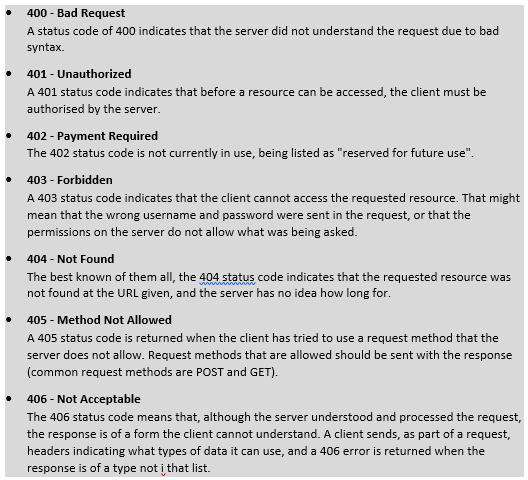

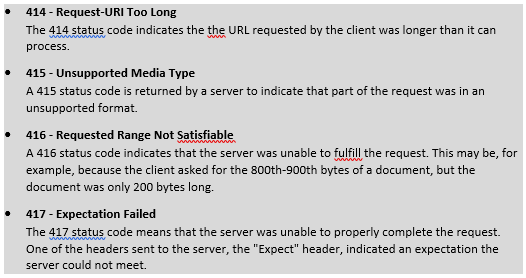
5XX Information

Redirection
HTTP allows servers to redirect a client request to a different location. Although, this will usually result in another network round trip, it has some useful applications:
- A web application may use redirection to navigate between parts of the application.
- If content has moved to a different URL or domain name, redirection can be used to avoid breaking old URLs or bookmarks.
- It is possible to convert a POST request to a GET request using redirection.
- A client can be directed to use its local cache for content that has not changed.
- A server specifies redirection by returning a 3xx status code:

How redirection happens actually that I show in pictorial form as below:

The above picture shows, how redirection happens on behalf of status code. All of these status codes require the URL of the redirect target to be given in the Location: header of the HTTP response.
All of these status codes require the URL of the redirect target to be given in the Location: header of the HTTP response.
Example HTTP response for a 301 redirect
A HTTP response with the 301 “moved permanently” redirect looks like this: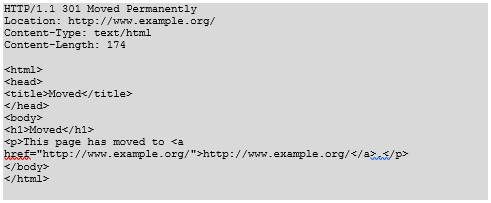
Cross Domain
To understand what is cross domain, let’s understand Ajax request. Suppose you need to populate states on the selection of country and you don’t want to reload the page again for each request. So what we do is we send a silent request (i.e. Ajax request) from back ground and get the particular contain and using the help of JavaScript and reloads the only the stat’s dropdown. SO it get loaded and page doesn’t get refreshed. So suppose A.com want to read data from B.com and both are different servers. Pulling data form another domain is called cross domain.
Following are the pictorial representation of the cross domain request. The following will show what all the steps happens when we send the request cross domain.
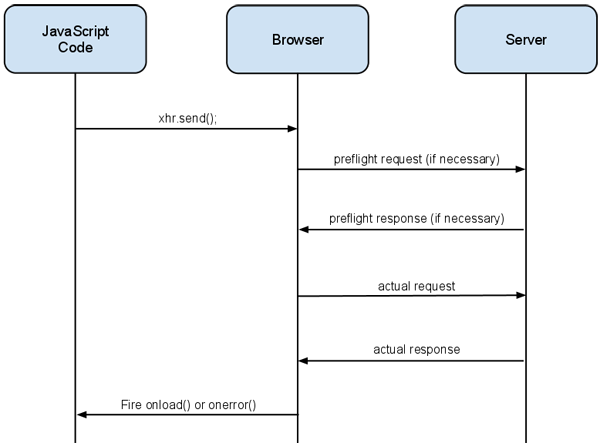
Preflight / Preflight requests
- Unlike simple requests (discussed above), “preflighted” requests first send an HTTP request by the OPTIONS method to the resource on the other domain, in order to determine whether the actual request is safe to send. Cross-site requests are preflighted like this since they may have implications to user data. In particular, a request is preflighted if:
- It uses methods otherthan GET, HEAD or POST. Also, if POST is used to send request data with a Content-Type other than application/x-www-form-urlencoded,multipart/form-data, or text/plain, e.g. if the POST request sends an XML payload to the server using application/xml or text/xml, then the request is preflighted.
An example:
When performing certain types of cross-domain AJAX requests, modern browsers that support CORS will insert an extra “preflight” request to determine whether they have permission to perform the action.
Preflight Request:
Preflight Response:

In the above request and response the “Access-Control-Request-Method” sends the requested method and in response server sends Allowed methods, which are accepted by servers.
Multipart Request
What is multipart?
A HTTP multipart request is a HTTP request that HTTP clients construct to send files and data over to a HTTP Server. It is commonly used by browsers and HTTP clients to upload files to the server.
Thus, a typical multipart Content-Type header field might look like this:
Content-Type: multipart/mixed;
boundary=gc0p4Jq0M2Yt08jU534c0p
This indicates that the entity consists of several parts, each itself with a structure that is syntactically identical to an RFC 822 message, except that the header area might be completely empty, and that the parts are each preceded by the line
–gc0p4Jq0M2Yt08jU534c0p
Example:
<html>
<head>
<title>File Upload</title>
<meta http-equiv=”Content-Type” content=”text/html; charset=UTF-8″> </head>
<body>
<form method=”POST” action=”upload” enctype=”multipart/form-data” >
File: <input type=”file” name=”file” id=”file” />
<br/>
Destination: <input type=”text” value=”/tmp” name=”destination”/>
</br>
<input type=”submit” value=”Upload” name=”upload” id=”upload” />
</form>
</body>
</html>
This is what submitted data from the fileupload form looks like, after selecting sample.txt as the file that will be uploaded to the tmp directory on the local file system:
POST /fileupload/upload HTTP/1.1
Host: localhost:8080
Content-Type: multipart/form-data;
boundary=—————————263081694432439
Content-Length: 441
—————————–263081694432439
Content-Disposition: form-data; name=”file”; filename=”sample.txt”
Content-Type: text/plain
Data from sample file
—————————–263081694432439
Content-Disposition: form-data; name=”destination”
/tmp
—————————–263081694432439
Content-Disposition: form-data; name=”upload”
Upload
—————————–263081694432439–
Therefore it is clear that:
- Content-Type: multipart/form-data; boundary=—————————9051914041544843365972754266 sets the content type to multipart/form-data and says that the fields are separated by the given boundary string.
- every field gets some sub headers before its data:
Content-Disposition: form-data;, - the field name, the filename, followed by the data.
- The server reads the data until the next boundary string. The browser must choose a boundary that will not appear in any of the fields, so this is why the boundary may vary between requests.
- Because we have the unique boundary, no encoding of the data is necessary: binary data is sent as is.