
Supervised Fine Tuning (SFT) – Improving Models for Particular Scenarios
The painstaking process that is the evolution of Artificial Intelligence (AI) has yielded exceptionally complex models capable of a variety of tasks, each performed with astounding efficiency. Unfortunately, these models often lack one crucial element: versatility. This is where Supervised Fine Tuning (SFT) proves to be useful. In short, SFT is an important phase in the process of applying a pre-trained model to specific tasks and improving its performance on those applications. In this blog, we will try to understand the methodology as well as the practical implications of supervised fine tuning, its applications, and also the best practices associated with it.
Comprehending Supervised Fine Tuning (SFT)
SFT requires an already trained model, commonly a large language model (LLM) or vision model. The pre-trained model requires some retraining so that it can be appended to a specific task with tagged data. The general domain model knows a lot due to working with big datasets but SFT helps narrow it down to the subtleties of a specific area or domain of interest.
SFT typically focuses on:
- Domain Adaptation: Aligning the model to specialized knowledge in fields like healthcare, finance, or legal services.
- Task Specialization: Fine-tuning the model for tasks such as sentiment analysis, question answering, or text summarization.
- Performance Optimization: Improving metrics like accuracy, precision, recall, and F1-score for specific use cases.
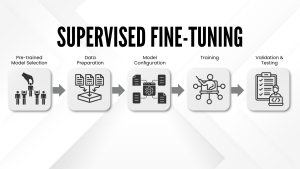
The SFT Workflow
The process of supervised fine-tuning can be broken down into the following key steps:
– Pre-trained Model Selection
The first step is to select an appropriate pre-trained model. Common choices include BERT, GPT, or T5 for NLP tasks, and ResNet or EfficientNet for computer vision tasks. The choice depends on the base architecture’s suitability for the target task.
– Data Preparation
Supervised fine-tuning requires labeled data that aligns with the target use case. Data preparation involves:
- Data Collection: Acquiring a dataset relevant to the task.
- Data Cleaning: Removing noise and inconsistencies from the data.
- Data Augmentation: Enhancing the dataset with techniques like paraphrasing (for NLP) or transformations (for vision).
- Data Annotation: Labeling the dataset if it is not already labeled.
– Model Configuration
Configuring the model involves setting up:
- Input and Output Layers: Modifying the architecture to accommodate task-specific inputs and outputs. For instance, adding a classification head for sentiment analysis.
- Hyperparameters: Selecting parameters such as learning rate, batch size, and number of epochs.
– Training
Training the model involves:
- Optimization Algorithm: Common choices include AdamW or SGD for gradient-based optimization.
- Loss Function: Selecting an appropriate loss function based on the task (e.g., cross-entropy loss for classification tasks).
- Evaluation Metrics: Monitoring metrics like accuracy or BLEU score during training.
– Validation and Testing
After training, the model is validated on a separate dataset to monitor overfitting. Testing on a holdout set provides a final measure of the model’s performance.
– Deployment
The fine-tuned model is deployed to production environments for real-world usage. Continuous monitoring and retraining may be necessary to adapt to new data or changing requirements.
Best Practices for SFT
- Dataset Quality : The quality of the labeled dataset directly impacts the performance of the fine-tuned model. Investing in high-quality annotations and diverse data points is crucial.
- Hyperparameter Tuning: Systematic tuning of hyperparameters can significantly improve the model’s performance. Techniques like grid search or Bayesian optimization can be used.
- Regularization: Applying regularization techniques like dropout or weight decay prevents overfitting during fine-tuning.
- Transfer Learning Insights: Understanding the layers of the pre-trained model that contribute most to the task helps in freezing or fine-tuning specific layers. For instance, lower layers in vision models capture general features, while higher layers capture task-specific features.
Advanced Techniques in SFT
- Parameter-Efficient Fine-Tuning (PEFT) : Instead of fine-tuning all model parameters, PEFT techniques like adapters or prompt-tuning modify only a small subset of parameters, reducing computational requirements.
- Cross-Domain Fine-Tuning: Leveraging knowledge from multiple domains can enhance model generalization. For example, a legal chatbot fine-tuned on medical dialogues may benefit from the underlying conversational patterns.
- Multi-Task Learning: Training a model on multiple related tasks simultaneously improves its ability to generalize and reduces the need for separate fine-tuning efforts.
The Future of SFT
As AI models continue to grow in scale and complexity, the importance of fine-tuning for specific use cases will only increase. Advances in techniques like PEFT and the emergence of foundational models trained on even broader datasets will make fine-tuning more accessible and efficient. Additionally, tools like Hugging Face’s Transformers library and TensorFlow’s Model Garden are simplifying the SFT process, enabling developers to achieve state-of-the-art performance with minimal effort.