
As AI technology rapidly advances, the integration of language models like OpenAI’s GPT-4 into various applications has become increasingly prevalent. One of the most powerful features of these models is their ability to call functions directly, enabling developers to create more dynamic and responsive applications. However, to harness this capability effectively, adhering to best coding practices is essential. This blog explores some key best practices for OpenAI function calling, ensuring robust and efficient application development.
Understand the Use Case:
Before diving into code, it’s crucial to clearly define the problem you’re trying to solve and how function calling fits into your solution.
Ask yourself:
- What specific tasks will the AI handle?
- How will the AI’s function calls improve the application’s performance or user experience?
- What are the limitations and boundaries of the function calls?
A clear understanding of your use case helps in designing a more focused and efficient solution.
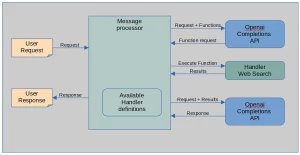
High-level workflow of the function calling feature in the Completions API is as follows:
- A user makes a request.
- The message processor (application code) converts this request into a message prompt. It also appends a list of supportable functions (such as ‘web search’ or ‘execute os command’) to the prompt.
- This message prompt is then sent to the Completions API. If the AI model determines that it needs additional information to fulfill the request, it checks the list of supportable functions provided. If it finds a relevant function, it returns a request to execute that function along with the necessary parameters.
- Upon receiving this function request, the message processor uses appropriate handlers to execute the function.
- The results of the function execution and the original request are then sent back to the Completions API.
- The Completions API then uses this information to formulate a response to the original user’s request.
- Finally, this response is sent back to the user.
Defining Functions:
funcDef = { "name": "file_save", "description": "save code or text into a file", "parameters": { "type": "object", "properties": { "directory_path": { "type": "string", "description": "the location of the file to be saved", }, "file_name": { "type": "string", "description": "the name of the file to be saved", }, "file_content": { "type": "string", "description": "the content of the file to be saved", }, }, "required": ["directory_path", "file_name", "file_content"], }, }
- The definition describes the function, the model uses this when matching functions with some need for information it has.
- The definition lists and describes the parameters needed to execute the function.
- A set of function definitions can then be passed to the API when making a request, enabling the model to store text and code to the local file system.
Calling the Completions API:
def get_completionWithFunctions(messages ,functions:str, temperature:int=0, model:str="gpt-3.5-turbo-0613", max_retries:int=3, retry_wait:int=1): logging.info(f'get_completionWithFunctions start: model {model} functions {functions} messages {messages}') retries = 0 while retries <= max_retries: try: response = openai.ChatCompletion.create( model=model, messages=messages, functions=functions, function_call = "auto", temperature=temperature, ) logging.info(f'get_completion end: {model}') response_message = response["choices"][0]["message"] return response_message except RateLimitError as e: if retries == max_retries: raise e retries += 1 print(f"RateLimitError encountered, retrying... (attempt {retries})") time.sleep(retry_wait)
Processing a user request:
When the model processes a user request requiring additional information, it uses the provided list of functions.
If the user request is ‘please write python code to compute the first N primes and save the code in primes.py,’ the model can generate the code and, being aware of the ‘file_save’ function, respond with a request to save the file.
The code that calls the get_completionWithFunctions() method then checks the response for a function call request:
Besides selecting model versions that support function calling, the main difference is that the set of function definitions is sent to the API via the functions parameter, as shown below:
function_calling_definition = self.handler.get_function_calling_definition() max_iterations = 5 itr = 0 for i in range(max_iterations): #completion_messages = [{"role": "user", "content": message}] #default is gpt-3.5-turbo-0613 you can alos use gpt-4-0613 response_message = get_completionWithFunctions(completion_messages, function_calling_definition, 0, model) #check if a function call is requested if response_message.get("function_call"): action = [] function_name = response_message["function_call"]["name"] function_args_text = response_message["function_call"]["arguments"] function_args = json.loads(function_args_text) #extract the paramters and nane of the function reqested action_dict = dict() action_dict["action_name"] = function_name for key, value in function_args.items(): action_dict[key] = value #execute the function if available response = self.handler.process_action_dict(action_dict, account_name) response_message_text = QuokkaLoki.handler_repsonse_formated_text(response) completion_messages.append(response_message) completion_messages.append( { "role": "function", "name": function_name, "content": response_message_text, } ) else: break
Overall, this example highlights two key capabilities made possible by function calling: real-time web search and web text scraping. These functions enable the AI to not only generate responses based on its training data but also fetch and present real-time, up to-date information from the web, making it a highly dynamic and powerful tool for users.
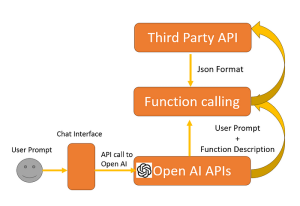
Structure Your Prompts Carefully:
The prompt is the foundation of any interaction with OpenAI models. Crafting well structured prompts ensures that the model understands your intent and performs the desired function calls correctly.
Be Specific: Clearly specify the function to be called and the parameters required. Provide Context: Give the model enough context about the task to minimize ambiguity. Use Consistent Formatting: Consistency in prompt structure helps the model learn and respond more accurately.
Validate Inputs and Outputs:
To ensure reliability and accuracy, validate the inputs before passing them to the AI model and the outputs returned from the function calls.
Input Validation: Check that all required parameters are provided and are of the correct type and format.
Output Validation: Verify that the output meets the expected criteria and handle any discrepancies gracefully.
Handle Errors Gracefully:
Error handling is crucial for maintaining the stability and reliability of your application. Implement robust error handling mechanisms to catch and manage exceptions that may occur during function calls.
Catch Specific Exceptions: Catch and handle specific exceptions to provide more informative error messages.
Retry Mechanism: Implement a retry mechanism for transient errors. Fallback Strategy: Have a fallback strategy in place if the AI function call fails.
Optimize API Usage :
- Efficient use of the OpenAI API ensures better performance and cost management. • Batch Requests: Where possible, batch multiple requests into a single API call to reduce latency and API usage.
- Rate Limiting: Be mindful of the API rate limits and implement rate limiting in your application to avoid hitting the limits.
- Cache Responses: Cache responses for frequently requested data to reduce API calls and improve response times.
Monitor and Log:
- Monitoring and logging are essential for diagnosing issues and understanding how your application interacts with the OpenAI API.
- Log Requests and Responses: Log all API requests and responses for auditing and debugging purposes.
- Monitor Performance: Continuously monitor the performance of your application and the API calls to identify and address bottlenecks.
Ensure Security and Privacy:
- Handling sensitive data with AI requires strict adherence to security and privacy best practices.
- Data Encryption: Encrypt data in transit and at rest to protect it from unauthorized access.
- Access Controls: Implement strict access controls to ensure only authorized users and systems can interact with the OpenAI API.
Data Anonymization: Where possible, anonymize sensitive data before sending it to the API.
Conclusion:
Implementing OpenAI function calling can significantly enhance your application’s capabilities. By following these best practices, you can ensure that your use of OpenAI’s function calling is efficient, reliable, and secure. Remember to always stay updated with the latest developments and guidelines from OpenAI to continually improve your application’s integration with their API.