
Mixture of Experts (MoE) Models: The Future of Scaling AI
In the ever-evolving landscape of artificial intelligence (AI), the quest for models that are both powerful and efficient has led us to explore innovative architectures. One such groundbreaking approach that has captured our attention is the Mixture of Experts (MoE) model. This architecture not only promises enhanced performance but also offers a scalable solution to the growing demands of AI applications.
Understanding Mixture of Experts (MoE)
At its core, a Mixture of Experts model is designed to divide complex tasks among specialized sub-models, known as “experts.” Each expert is trained to handle a specific subset of the input data, allowing the overall system to leverage specialized knowledge for different aspects of a problem. A gating network plays a crucial role by dynamically selecting the most relevant experts for each input, ensuring that the right expertise is applied to the right task.
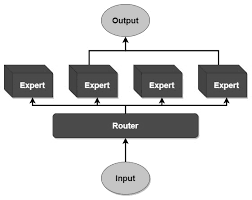
Benefits of MoE in Scaling AI
In the course of gradually developing AI, we have come to appreciate certain undeniable benefits of MoE models:
Efficiency: Activation of only a subset of experts per input allows for lower computation than traditional architectures that treat each input uniformly by activating all parameters.
Scalability: More complex tasks can be handled as more experts are added to the system without commensurately increasing computational cost, presenting a favorable scaling option for MoE with respect to AI models.
Specialization: Due to enhanced specialization in a subdomain of data by each expert, the model captures finer patterns that may be advantageous to general performance across an array of tasks.
Milestones about our Journey with MoE Models
To build even better AI systems, we are using an MoE architecture in our ecosystem. This acts as a catalyst and provides us with a different perspective to model development and deployment.
Strategies to Implement
We start out already by identifying tasks in the project that would benefit from being specialized. For NLP, some experts would be chosen to handle syntax, while others would take on formal semantics. By splitting these roles, we can target our models more accurately to the intricacies of language.
We train these experts with data assigned to them according to their specialization. The gating network is trained to indicate the best experts for each input so that they can work together.
On the Path to Challenges
The MoE models posed challenges from the start, especially in terms of increasing the complexity of training from multiple experts while ensuring efficient communication between them. These challenges were alleviated by establishing some advanced training techniques and further optimizing infrastructure to allow for dynamic operation of MoE architecture.
Real-World Applications and Impact
The implementation of MoE models has yielded significant improvements in various applications:
- Natural Language Processing: By deploying MoE models, we’ve achieved more accurate language understanding and generation, as each expert brings a deep focus to different linguistic aspects.
- Computer Vision: In image recognition tasks, MoE models have enabled us to dissect visual data more effectively, with experts specializing in recognizing textures, shapes, or colors.
- Recommendation Systems: Personalized recommendations have become more precise, as MoE models allow us to cater to the diverse preferences of users by leveraging specialized experts.
The Future of MoE in AI
Looking ahead, we are excited about the potential of MoE models to revolutionize AI scalability. The ability to add and train new experts as needed offers a flexible pathway to expanding model capabilities without incurring prohibitive computational costs.
Moreover, the AI community’s growing interest in MoE architectures suggests a collaborative effort toward refining these models. Innovations in training methodologies, expert allocation strategies, and gating mechanisms are on the horizon, promising even greater efficiency and effectiveness.