
Large Language Models (LLMs) are at the forefront of artificial intelligence, powering applications from chatbots and translators to content generators and personal assistants. These models, such as OpenAI’s GPT-4, have revolutionized how we interact with machines by understanding and generating human-like text.
How Large Language Models Work:
Large language models are functions that map text to text. Given an input string of text, a large language model predicts the text that should come next.
The magic of large language models is that by being trained to minimize this prediction error over vast quantities of text, the models end up learning concepts useful for these predictions.
Let’s try to understand where LLMs fit in the world of Artificial Intelligence.
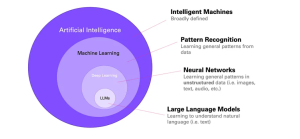
The field of AI is often visualized in layers:
Artificial Intelligence (AI): Encompasses the creation of intelligent machines.
Machine Learning (ML): A subset of AI focused on recognizing patterns in data.
Deep Learning: A branch of ML dealing with unstructured data (text, images) using artificial neural networks inspired by the human brain.
Large Language Models (LLMs): A subfield of Deep Learning that specifically handles text. This will be the focus of this article.
But how exactly do they work? Let’s delve into the mechanisms that make LLMs so powerful.
- The Foundation: Neural Networks
At the core of any language model is a neural network. Neural networks are computational systems inspired by the human brain’s structure and function. They consist of layers of interconnected nodes (neurons) that process data through weighted connections. In the case of LLMs, the neural network architecture is typically called a Transformer.
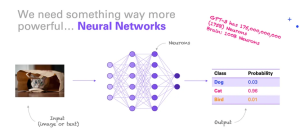
The Transformer Architecture
Introduced in the paper “Attention is All You Need” by Vaswani et al., the Transformer architecture has become the backbone of most state-of-the-art LLMs. It uses a mechanism called self-attention, which allows the model to weigh the importance of different words in a sentence relative to each other. This ability to focus on various parts of the input text gives Transformers a significant advantage in understanding the context and relationships within the text.
- Training: Learning from Massive Datasets
Training an LLM involves exposing it to vast amounts of text data, often encompassing diverse sources such as books, articles, websites, and more. This process allows the model to learn the statistical properties of language, such as grammar, vocabulary, and even some level of common sense reasoning.

Pretraining
During pretraining, the model learns to predict the next word in a sentence given the previous words. This task, known as language modeling, helps the model understand language structure and usage. Pretraining is computationally intensive and requires substantial resources, often taking weeks or months on powerful hardware.
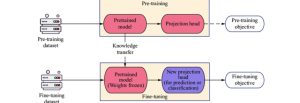
Fine-Tuning
After pretraining, the model undergoes fine-tuning on specific tasks or domains to improve its performance in those areas. For instance, a model might be fine-tuned for sentiment analysis, translation, or customer support chatbots. Fine-tuning involves training the model on a narrower dataset relevant to the task, and adjusting its parameters to optimize performance.
- Inference: Generating Text
Once trained, the model can be used for inference, generating text based on a given input. The input could be a prompt, a question, or an incomplete sentence, and the model predicts the most likely continuation based on its training.
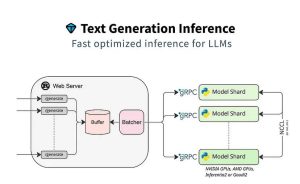
- Applications and Future Directions
LLMs have a wide range of applications:
Chatbots and Virtual Assistants: Providing human-like interactions and support.
Content Creation: Assisting in writing articles, stories, and marketing copy.
Language Translation: Offering accurate and nuanced translations between languages.
Healthcare: Supporting diagnostics, patient interactions, and medical research.
How to control a large language model?
Of all the inputs to a large language model, by far the most influential is the text prompt.
Large language models can be prompted to produce output in a few ways:
Instruction: Tell the model what you want
Completion: Induce the model to complete the beginning of what you want
Scenario: Give the model a situation to play out
Demonstration: Show the model what you want, with either:
-A few examples in the prompt
-Many hundreds or thousands of examples in a fine-tuning training dataset
An example of each is shown below:
Instruction prompts
Write your instruction at the top of the prompt (or at the bottom, or both), and the model will do its best to follow the instruction and then stop. Instructions can be detailed, so don’t be afraid to write a paragraph explicitly detailing the output you want, just stay aware of how many tokens the model can process.
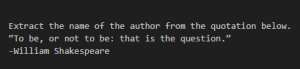
Example instruction prompt:
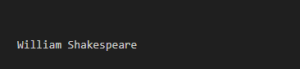
Output:
Completion prompt example
Completion-style prompts take advantage of how large language models try to write text they think is mostly likely to come next. To steer the model, try beginning a pattern or sentence that will be completed by the output you want to see. Relative to direct instructions, this mode of steering large language models can take more care and experimentation. In addition, the models won’t necessarily know where to stop, so you will often need stop sequences or post-processing to cut off text generated beyond the desired output.
Example completion prompt:
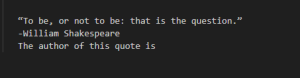
Output:
Scenario prompt example
Giving the model a scenario to follow or role to play out can be helpful for complex queries or when seeking imaginative responses. When using a hypothetical prompt, you set up a situation, problem, or story, and then ask the model to respond as if it were a character in that scenario or an expert on the topic.
Example scenario prompt:
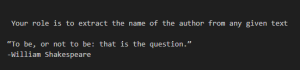
Output:
Demonstration prompt example (few-shot learning)
Similar to completion-style prompts, demonstrations can show the model what you want it to do. This approach is sometimes called few-shot learning, as the model learns from a few examples provided in the prompt.
Example demonstration prompt:
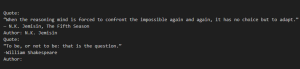
Output:
Fine-tuned prompt example
With enough training examples, you can fine-tune a custom model. In this case, instructions become unnecessary, as the model can learn the task from the training data provided. However, it can be helpful to include separator sequences (e.g., -> or ### or any string that doesn’t commonly appear in your inputs) to tell the model when the prompt has ended and the output should begin. Without separator sequences, there is a risk that the model continues elaborating on the input text rather than starting on the answer you want to see.
Example fine-tuned prompt (for a model that has been custom trained on similar prompt-completion pairs):
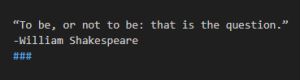
Output:
Code Capabilities
Large language models aren’t only great at text – they can be great at code too. OpenAI’s GPT-4o model is a prime example.
GPT-4o,GPT-4 is more advanced than previous models like gpt-3.5-turbo-instruct. But, to get the best out of GPT-4 for coding tasks, it’s still important to give clear and specific instructions. As a result, designing good prompts can take more care.
More prompt advice
For more prompt examples, visit OpenAI Examples.
In general, the input prompt is the best lever for improving model outputs. You can try tricks like:
–Be more specific: For example, if you want the output to be a comma-separated list, ask it to return a comma-separated list. If you want it to say “I don’t know” when it doesn’t know the answer, tell it “Say ‘I don’t know’ if you do not know the answer.” The more specific your instructions, the better the model can respond.
-Provide Context: Help the model understand the bigger picture of your request. This could be background information, examples/demonstrations of what you want, or explaining the purpose of your task.
-Ask the model to answer as if it was an expert: Explicitly asking the model to produce high-quality output or output as if it was written by an expert can induce the model to give higher quality answers that it thinks an expert would write. Phrases like “Explain in detail” or “Describe step-by-step” can be effective.
-Prompt the model to write down the series of steps explaining its reasoning: If understanding the ‘why’ behind an answer is important, prompt the model to include its reasoning. This can be done by simply adding a line like “Let’s think step by step” before each answer.